本周(3.20~3.25)的AI大新闻总览

本周(3.20~3.25)的AI大新闻总览:
又是大新闻爆炸的一周,码农帮手Cursor,设计师的AI工具Adobe firefly,Google的ChatGPT 「Bard」,Bing Image Creator,以及ChatGPT Plugins等,目不暇接,引人焦虑。
前一周的请看此条:
Cursor.so 发布,
Cursor.so 是集成了 GPT-4 ,对表Github Copilot的优秀而强大的免费代码生成器。 它支持多种编程语言,可以根据你的输入和需求自动生成代码片段。

其最大特点是免费,接入了GPT-4因此代码质量高于Github Copilot(其内部也集成了Github Copilot)。同时因为也集成了ChatGPT,可以直接在界面上进行问答。另外,不同于Github Copilot仅支持VS Code,它可以支持很多主流IDE。

直接在IDE中问答
但是这里有个坏消息:根据 @dotey 提供的情报,Cursor.so已经删除GPT-4的宣传语,现在使用的是GPT-3.5。
Adobe宣布发布Firefly。
Firefly 是 Adobe 推出的人工智能绘画工具,主要功能是图像生成和艺术字体效果。 它能够根据文本提示词创建图像,并提供数百种风格可以对结果进行调整。
https://www.adobe.com/sensei/generative-ai/firefly.html


文字生成图像范例,类似于Midjourney
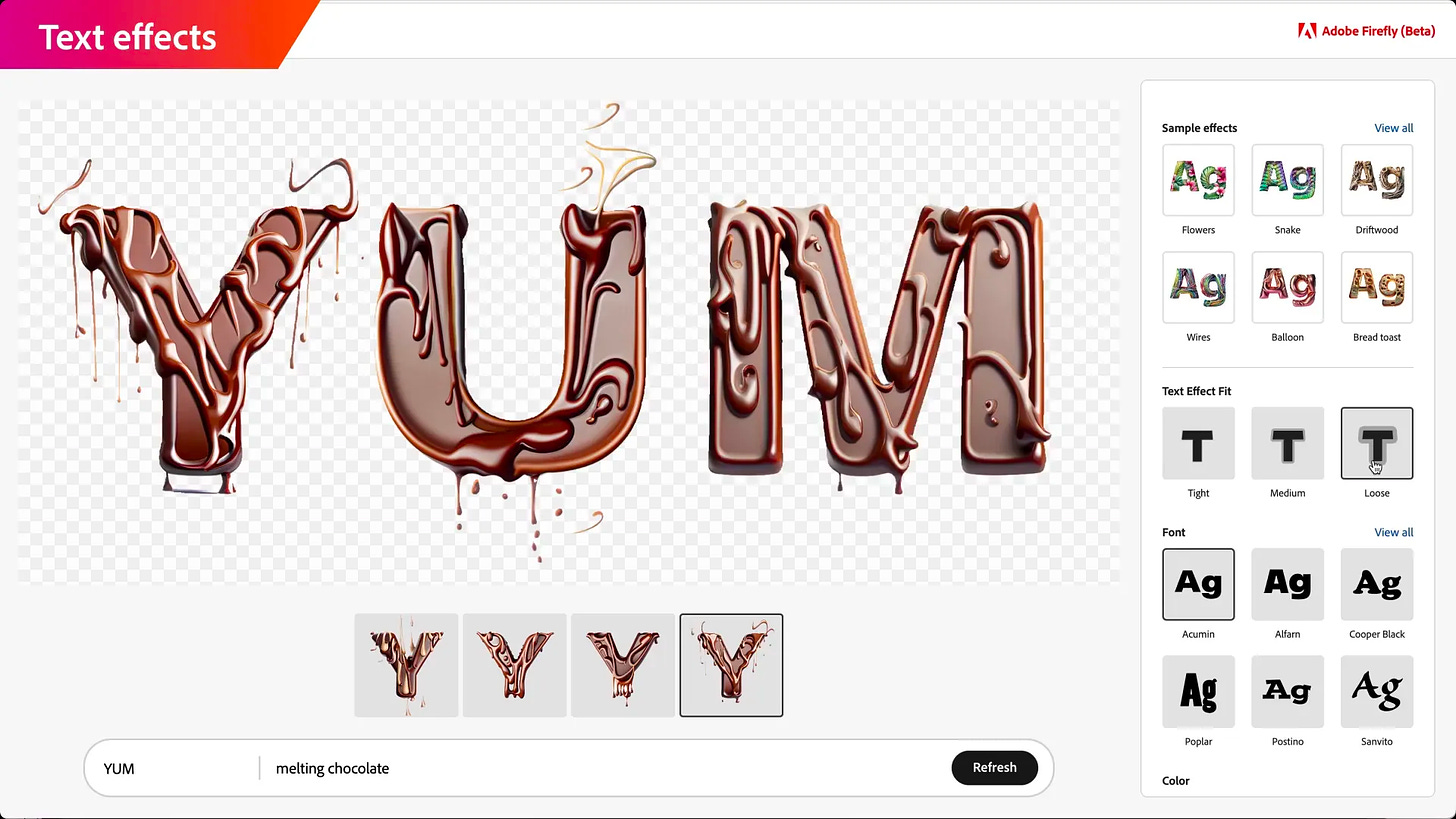
文字效果/艺术字 范例
申请链接:
这一天还有个大新闻:Google的Bard正式公测。(虽然只有美国和英国IP能够申请。)
根据各种体验者的报告,在英文上,虽然稍逊一筹不过和ChatGPT算是能打的有来有回。最大的问题是:暂时不支持多语言,也不会写代码。
GTC2023 中,NVIDIA宣布提供生成式AI的云服务,并发布针对LLM优化的NVIDIA H100 NVL,老黄称之为比「当前唯一可以实际处理 ChatGPT 的 GPU」HGX A100快10倍。
同一天,Bing Image Creator发布。它是微软基于人工智能技术推出的在线 AI 绘图工具,能够通过图像创建者让使用者以文字叙述快速生成图片。它是基于 OpenAI 的 DALL-E 模型的先进版本,已经整合到新版的 Bing 和 Edge 浏览器中。
https://twitter.com/bing/status/1638164442583117824
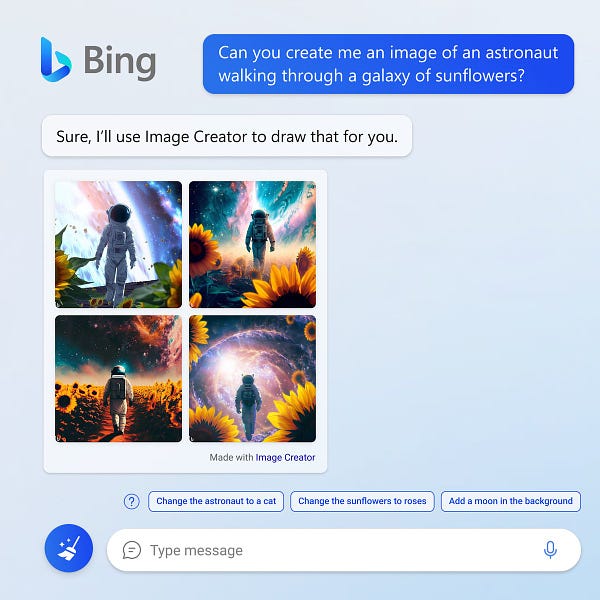
https://twitter.com/bing/status/1638164442583117824
无需new bing的试玩:
3月23日:微软正式推出Microsoft Loop。
Microsoft Loop 是一款新的协作画布,允许团队跨 Microsoft 365 应用程序进行协作。 Loop 的组件、页面和工作空间都建立在微软的 Fluid Framework 开源平台上。
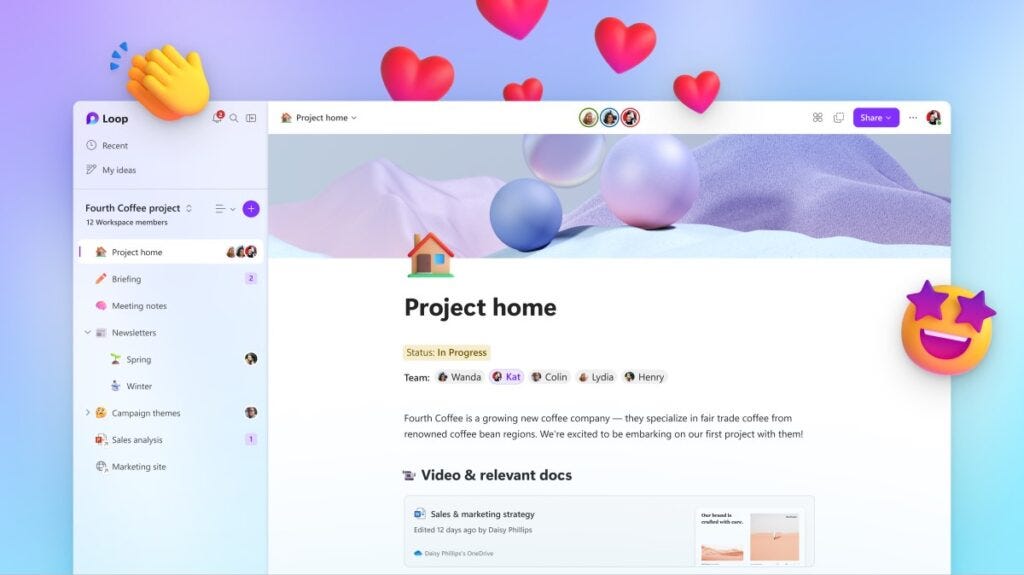
可以看出Microsoft Loop完全就是对标Notion,连Notion AI他们都有一个类似的,就是上周提到的Microsoft 365 Copilot:
同一天,Canva出了十个AI能力来对标Adobe firefly

详细说明请看解析:
https://twitter.com/op7418/status/1638859716360278022?s=20
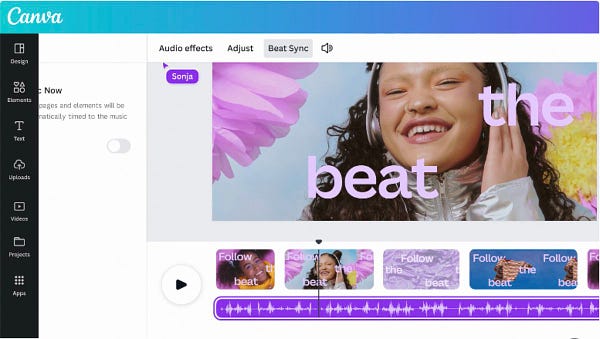
https://twitter.com/op7418/status/1638859716360278022?s=20
大新闻来了!ChatGPT公布插件(Plugins)支持!
插件 (Plugins) 是专门为语言模型设计的工具,可帮助 ChatGPT 访问最新信息、运行计算或使用第三方服务,因此第三方开发商能够将自己的服务集成到 ChatGPT 的对话窗口中。首批开放的插件包括了酒店航班预订、外卖服务、在线购物、法律知识、专业问答、文字生成语音等。
OpenAI 官方提供的一个插件是最有杀伤力的:browsing插件。
它使用了 Bing 搜索 API,会用互联网上最新的信息来回答问题,并给出它的搜索步骤和内容来源链接。这意味着ChatGPT是个只有2021年之前知识的傻子已经成为了历史,现在它是有着互联网最新信息的傻子了(并不是)。

对于开发者:
这里有一个Plugin for ChatGPT的开发指南。
老规矩,这个也要排队,地址在这里:
https://openai.com/waitlist/plugins
Databricks开源了一款名为Dolly的LLM,并只用了60亿个参数就训练出了类似ChatGPT的指令跟随能力。神奇的事,这款模型并不是新开发的。

Dolly只有60亿参数,远少于GPT-3的1750亿,并且已有两年的历史,它能如此出色地工作是非常令人惊讶的。它的原理是采用来自EleutherAI的现有开源60亿参数模型,通过使用Alpaca的数据进行微调,使其具备原始模型中不存在的指令跟随功能。
为什么是开放模型?
Databricks相信像Dolly这样的模型将有助于推广LLM,将其从少数几家公司负担得起的东西变成每家公司都能拥有和定制以改进产品的商品,大多数ML用户通过直接拥有他们的模型能得到最好的长期服务。
仓库地址:https://github.com/databrickslabs/dolly
如果这篇有帮助,请订阅转发,也可以fo我的推特。我将带给你更多关于Web3,Layer2,AI,以及日本相关咨询:



